

By Lorna Bevan | Guest Writer
“We are so small against the stars, so large against the sky” Leonard Cohen.
This is a pivotal week when both the stakes and emotions run extremely high, when things could be blown way out of proportion.
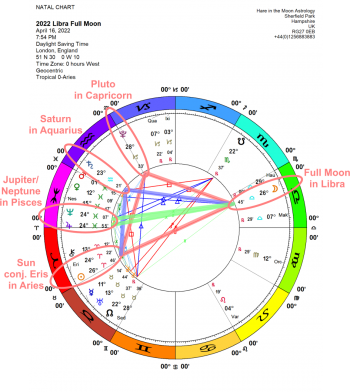
The rare coincidence of the great wave of dissolution that is the once in 166 years Jupiter/Neptune conjunction in Pisces and a Libra Full Moon tangling with Disruptor Eris, the Great Transformer Pluto and the Lord of Time and Karma Saturn marks a high tide, both globally and personally.
And everything is being overshadowed by the April 30th Taurus solar eclipse bringing karmic Scorpionic chickens home to roost.
We all need healing- we all need a space to rest and feel safe again. Be kind and gentle with yourself. Just to be alive as a human being on the planet right now means a raised level of stress -as you alternate between hypervigilance and shutting down. Simplify and streamline. Listen to your High Heart … your higher Self is speaking to you through extra sensory perception, psychic intuition, synchronicities, signs, symbols, dreams and insights. Trust your intuition as never before.
Flow with whatever happens -don’t cling to the crumbling river bank-it’s about to be washed away. Get more rest and hydration, immersing yourself in water as much as possible-following the ancient alchemists’ dictum of amplifying planetary energies by doing more of it.
For much more on how this Tsunami of Dissolution will sweep away your old life in the next 8 months, get my April 5D Report.
12 Reports per year for only $4.48 /£3.40 per month or one payment of $52.71/£40 in the Shop at: www.hareinthemoonastrology.co.uk
Get your free April 10-17 2022 Week Ahead+ Personal Sign Forecasts at: www.hareinthemoonastrology.co.uk
Chandra Symbol Full Moon 26 Libra
A gypsy cart with a campfire nearby.
“Magical ways of life are just about gone. Our instinctual attunement to nature and to God is being trampled under. But the reclaimed, more advanced instincts, after individuality had gone as far as it could go, are becoming the conscience pulse of the planet in a more futuristic way. Wandering from pre-individual states through the maze of individuality into post-individual states–in midstream it is trying to pass as a fully individuated creature. But it is profoundly unstirred by the separative ego fireworks and just waiting for the next evolutionary move to sweep all of it away. Timelessly, inwardly witnessing the passing of worlds. And waiting expectantly for the time when people move out beyond themselves, and discover Cosmos and Earth as one and live in that place as though it never had been lost and the world had never turned against itself.” – Elias Lonsdale
Aries Weekly Forecast: April 10-17, 2022
Your emotions are likely to spill out all over this week. The rare merger of gas giants Jupiter and Pisces is in the deepest part of your chart where all sorts of repressed memories, defences and secrets are kept hidden. You may be waking up to a spiritual, soulful side of yourself that has been dormant for many years. As your own planet Mars enters this part of your chart, channel the energy into charity work or any compassionate action to help others. Saturday’s Full Moon in Libra highlights your partnerships. Pay attention, be empathetic and listen more than you speak.
Go with the flow.
Taurus Weekly Forecast: April 10-17, 2022
The great conjunction Jupiter and Neptune on April 12th lights up and expands your 11th house of groups, friends and networks, lifting you up on a wave of appreciation, kindness and popularity. You may attract many more clients or customers or write a blog or a post that goes viral for all the right reasons. More than this, your creativity knows no bounds-make sure you capture all those insights. As Mars and Venus cross through Pisces, you can turn those ideas into gold. Put yourself first around Saturday’s Full Moon-rest your body and mind and revive your soul.
On April 19th, the Sun returns to Taurus -get ready to welcome a year for the memory books.
Gemini Weekly Forecast: April 10-17, 2022
The very rare meeting between gas giants Jupiter and Neptune on Tuesday 12th is especially important for you as a Gemini, as it falls on the pinnacle of your chart. On April 14th when Mars joins Venus, Jupiter and Neptune here, the sky’s the limit. It looks as if a change of direction is about to happen. It’s been brewing in the background for a while but your rational voice has succeeded in ignoring it. Now your soul is speaking to you, through your intuition and your night time dreams. It’s time to pay attention. Get as much rest as possible around Saturday’s plutonic Full Moon and stay well away from others’ dramas and soap operas.
Waking up.
Cancer Weekly Forecast: April 10-17, 2022
It’s time to expand your world beyond the tight walls of your comfort zone. Tuesday’s once in 166 years merger between Jupiter and Neptune in fellow Water sign Pisces is amplified even more on Thursday 14th by Mars and Venus. Anything connected with publishing, studying, writing and travelling is very well starred. Find a way to throw a spanner into your usual routines and habits and spread your wings. You’re craving different forms of input, needing to meet new people and visit places you’ve never been. Refuse to allow Saturday’s plutonic Full Moon to affect your mood or your decisions, even if family rises or dramas erupt.
Your soul is speaking-pay attention.
Leo Weekly Forecast: April 10-17, 2022
This week, everyone’s emotions will be running high, including yours. Tuesday’s historic merger between Jupiter and Neptune in far seeing Pisces in your 8th House is a wakeup call to find a balance between 21st century consumerism and the needs of your soul. You may be handling large amounts of money, going through a divorce or feeling the pull towards a different life altogether. Under these influences, extravagance, gambling or recklessness is dangerous. Take off the rose-tinted glasses and walk the middle path. Knowing that on April 19th the Sun is going to light up the pinnacle of your chart-your angle of career- moving straight into the force field of the April 30th Taurus eclipse, think big but do nothing until after May 16th.
Doors are appearing where before there were only walls.
Virgo Weekly Forecast: April 10-17, 2022
Like it or not, the waters are rising very rapidly now and a huge wave of dissolution is washing away many of your old partnerships and alliances. As gas giants Jupiter and Neptune merge in your opposite sign of Pisces, emotions will also run high. You may be passionately in love, swept off your feet by a person or an idea or a project, but just make sure you check it all out very carefully before making an uncharacteristic leap of faith. Under this astrology, people can exaggerate or lie. It’s a perfect climate for hoaxers, scammers and gas lighters. Don’t get hooked into someone else’s big plan-keep a sense of perspective. Saturday’s Full Moon is all about your money. Double check your accounts.
Use you Virgoan super powers of discernment.
Libra Weekly Forecast: April 10-17, 2022
Tuesday April 12th brings the biggest planetary event of 2022-the conjunction of gas giants Jupiter and Neptune in Pisces. This is huge transpersonal energy and can feel overwhelming to us humans. That especially applies to you as a Libran, since it takes place in your angle of health and wellbeing. To avoid stress, burnout or illness, delegate some of your work or responsibilities, simplify as much as possible and get as much rest as you can. You’re going to be even busier from April 14th when Mars joins Venus in this same part of the sky, so cut yourself lots of slack now. On April 16th the annual Full Moon in your sign is at odds with Pluto-refuse to get involved in any arguments or dramas and do something relaxing just for you.
Pay attention to the signals your body is sending you.
Scorpio Weekly Forecast: April 10-17, 2022
The big event of 2022-the April 12th once in 166 years merger of gas giants Jupiter and Neptune-is happening in your 5th House. You might be falling in love with someone or something or throwing yourself totally into a project that is close to your heart. If you are involved in the arts whether creative, healing or spiritual, this overwhelming energy could send you up like a helium balloon, floating on cloud 9. As with everything, there’s a downside. Be extra vigilant for scammers and hoaxers-especially online-if it seems too good to be true, it probably is. Don’t take big risks around alcohol or drugs-watch your personal boundaries. Clear your schedule on April 16th at the Full Moon and get as much downtime as possible.
Ground yourself before you float away.
Sagittarius Weekly Forecast: April 10-17, 2022
Lucky you! Your personal planet expansive Jupiter is about to merge with Neptune on April 12 – a very rare cosmic event. This is the stuff of dreams and, in your chart, it’s lighting up anything connected with your home, your family and your parents. You are feeling warm, loving and empathetic towards your tribe, so let it show-you’ll get it back in spades. You might redecorate or plant a beautiful garden or host a party or dinner where everyone’s invited. Or throw open your home to someone who is need. The Full Moon on Saturday 16th reminds you that the people you work with are also part of your community.
At home in your own skin.
Capricorn Weekly Forecast: April 10-17, 2022
Tuesday’s historic conjunction between Jupiter and Neptune lights up your 3rd House. If you are a creative of any sort, prepare to be inspired. You might find yourself remembering a forgotten skill or talent, diving back into it and updating it to add to your current life. If you are self-employed, expect some light bulb moments when you suddenly see how you can expand your platforms to attract new clients. When action planet Mars joins Venus in this same part of your chart on April 14th, start turning inspiration into reality. The stunning Full Moon at the pinnacle of your chart is aligned with Transformer Pluto in your own sign- enhancing your career, your reputation and your public image.
All to play for.
Aquarius Weekly Forecast: April 10-17, 2022
The once in 166 years meeting between Jupiter and Neptune in Pisces is in your 2nd House of income, resources and personal security. The good news is that large sums of money may flood in but the bad news is that it could flow out almost as quickly. This energy can feel completely overwhelming, so knowing this in advance, find practical ways to stay grounded and remove those rose- tinted glasses. Online, be extra vigilant for get rich quick scams or cyber hoaxers. Thankfully, Venus is also in this part of the sky, helping you to re-balance after what has been a turbulent 18 months or so. Take some quite time for yourself around Saturday’s Full Moon.
Better times are just up ahead from the 19th when the Sun returns to Taurus.
Pisces Weekly Forecast: April 10-17, 2022
You certainly don’t need me to tell you that something very, very big is happening-you can sense the ground shifting under your feet. Tuesday’s historic conjunction of expansive Jupiter and farsighted Neptune is happening in your own sign, gifting you with enormous potential at the same time as overwhelming you emotionally. Think of it as a huge power surge that definitely needs to be earthed. Don’t resist the changes coming your way in the next 8 months but loosen your boundaries and go with the flow. You will be in the spotlight, so choose your moments carefully. Equally, if you have a big project or idea, launch it now, especially if it is humanitarian.
Look after your own energy so you can better support others.
Originally published at hareinthemoonastrology.co.uk and reproduced here with permission.
About the Author
Variously described as a visioneer, a creative disruptor, a life guide and a change maker, my passion is to blend the tools of Visionary Astrology and Transformational Coaching to help you to connect with your inner world so that you can transform your outer world. Through my practice, Hare In the Moon, I combine the ancient art of astrology with the modern art of personal coaching to offer clients all over the world a unique mix consultations and coaching services. I work with clients around the world by phone and email, tailoring my Astrology Coaching to each unique individual or business I work with.
I’m a qualified Psychological Astrologer, Jungian Psychotherapist and Master NLP Coach, and I’m currently taking a Master’s Degree in Analytical Astrology. I’ve had a varied career as a Modern Languages Teacher, a Management Development Consultant, a Counselling Clinician at Personal Performance Consulting Worldwide, a Personal and Career Coach and Psychotherapist, and former Consultant Astrologer for The Sunday Times Magazine.
You can learn more about my work or contact me at:
- https://www.hareinthemoonastrology.co.uk
- https://www.facebook.com/hareinthemoonastrology
- https://www.twitter.com/LornaBevan1